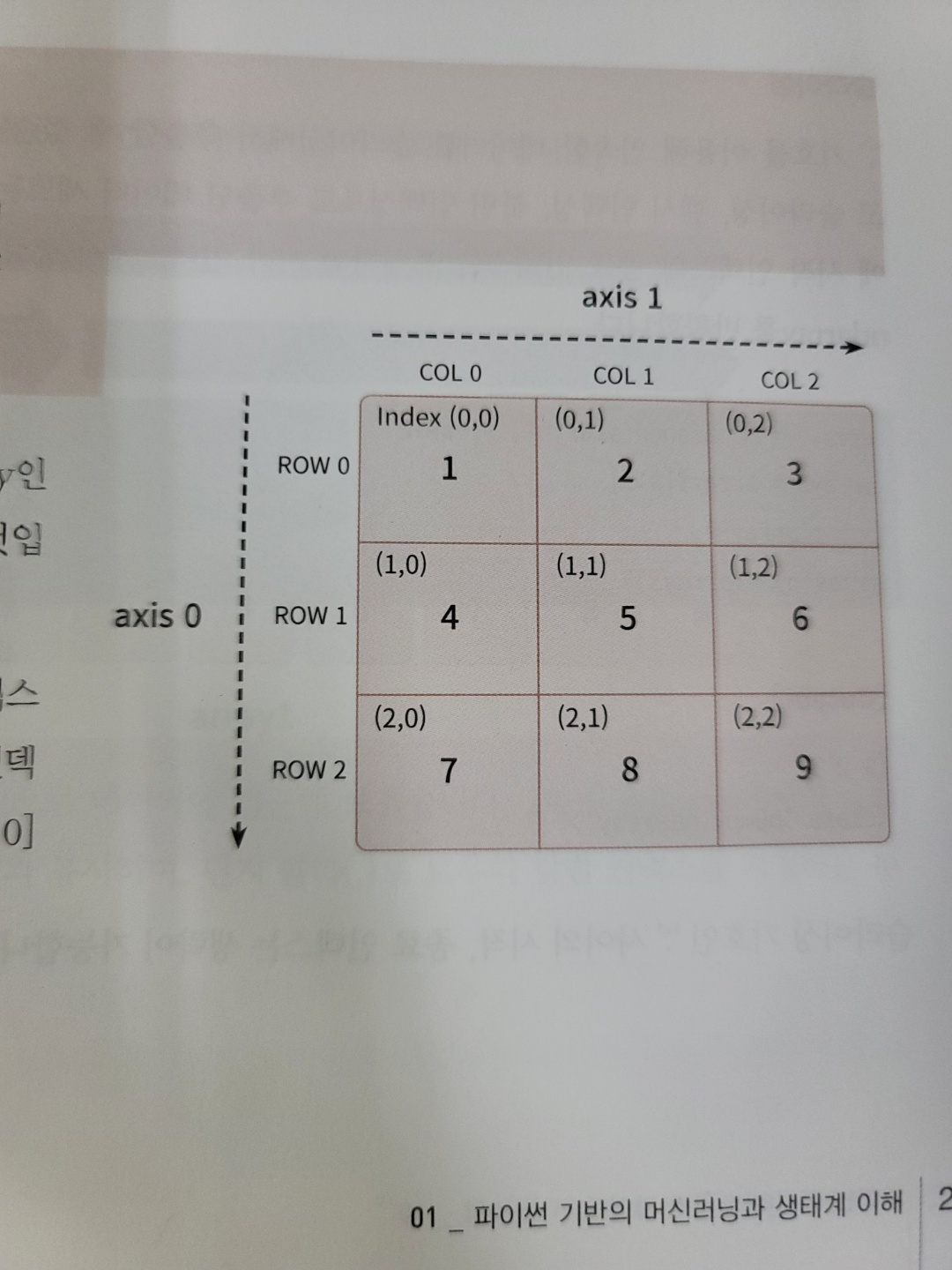
axis에 대한 고찰
axis 0
| row 방향의 축을 의미 |
axis 1
| column 방향의 축을 의미 |
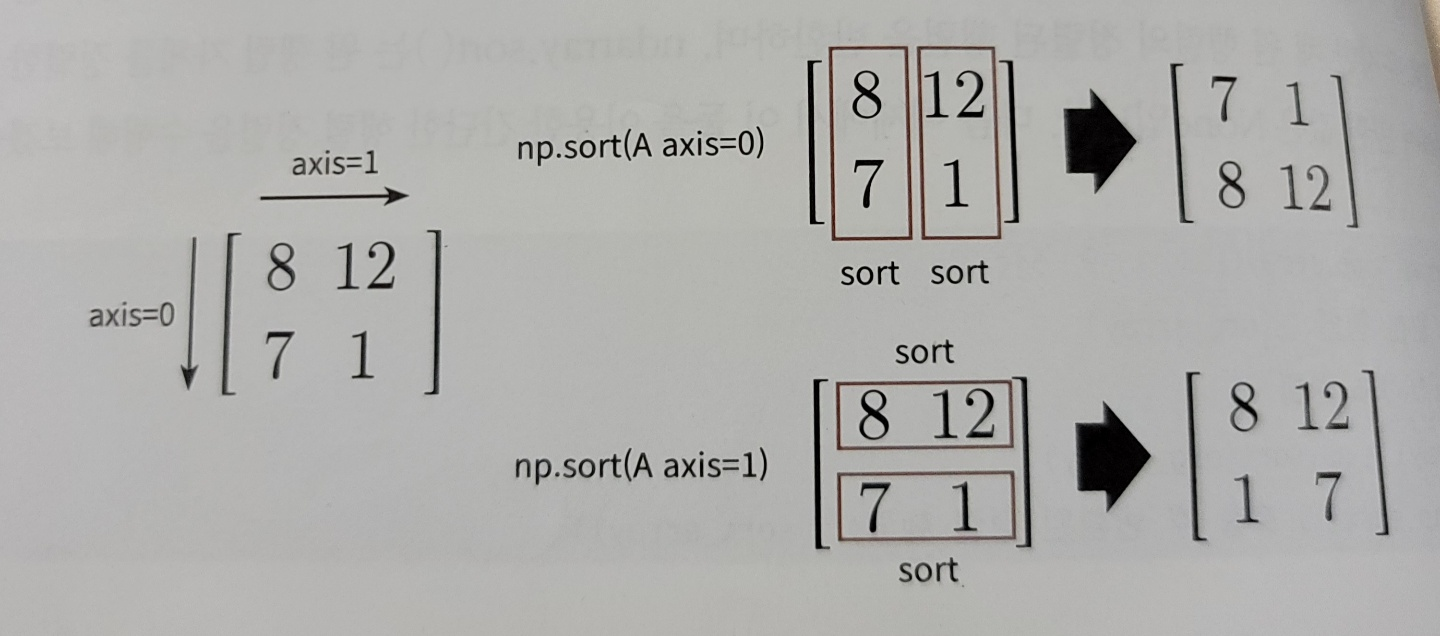
코드 적용 예시
array2d = np.array([[8, 12],
[7, 1 ]])
sort_array2d_axis0 = np.sort(array2d, axis=0)
print('로우 방향으로 정렬:\n', sort_array2d_axis0)
sort_array2d_axis1 = np.sort(array2d, axis=1)
print('컬럼 방향으로 정렬:\n', sort_array2d_axis1)
'''output
로우 방향으로 정렬:
[[ 7 1]
[ 8 12]]
컬럼 방향으로 정렬:
[[ 8 12]
[ 1 7]]
'''
내 의문: Numpy에서와 Pandas에서의 axis 속성 개념이 다르게 적용되는것 같은데??
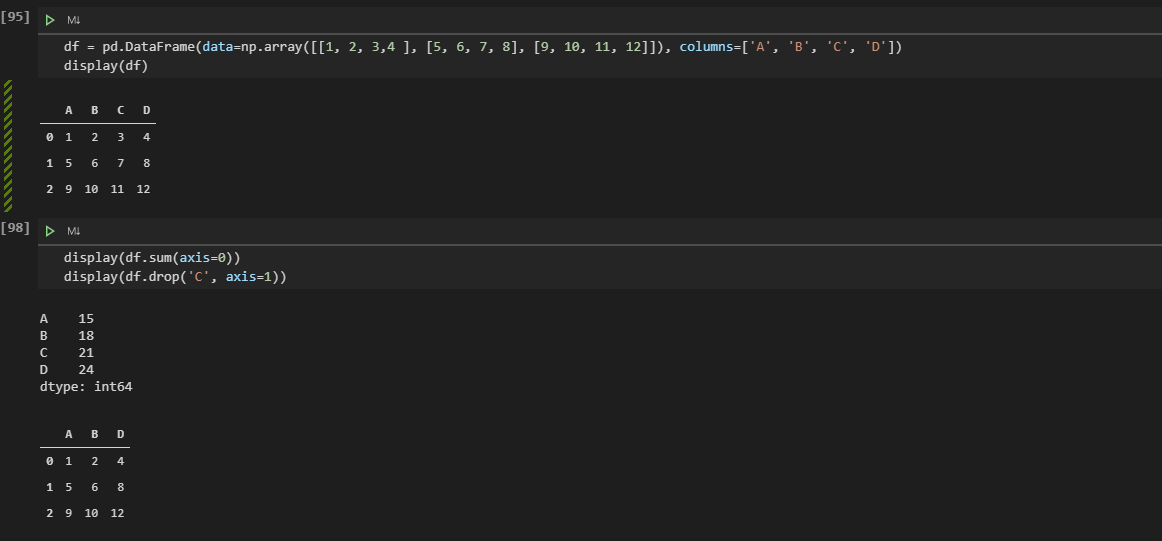
# sum에 대해서는 axis=0 각각의 column에 대해서 적용됨
pandas.sum(axis=0)
# 그러나 drop에서는 axis=1이 각각의 column에 대해서 적용됨
pandas.drop('C', axis=1)
내가 axis가 항상 어려웠던 이유가 이렇게 각 상황마다 내 생각과는 다르게 코드에 적용된다는 것 이었음.
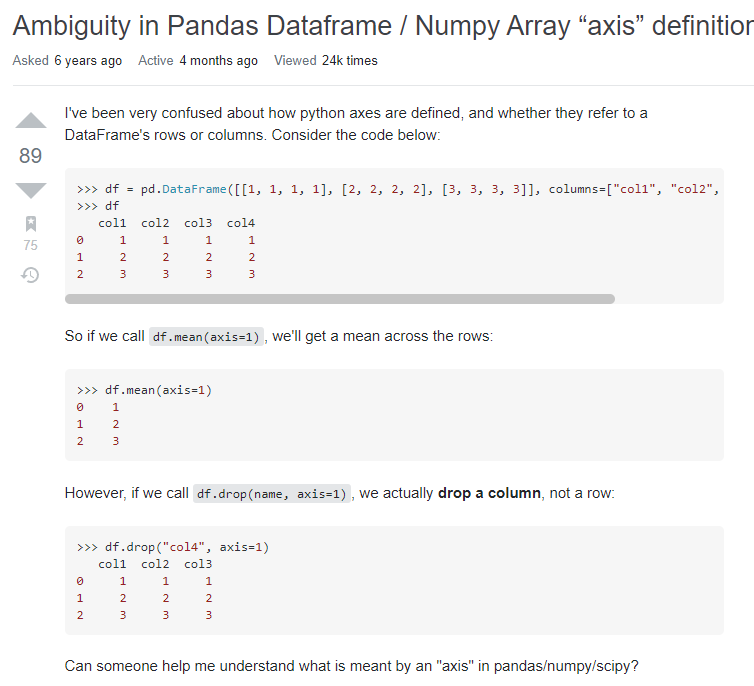
스택 오버플로우에서도 비슷한 질문이 올라옴

아직까지도 axis에 대해서 명쾌하게 이해가 되지는 않았지만 이런식으로 결과 형태를 먼저 생각하고 끼워 맞추는 식으로 하면 모든 함수들에 대해서 적용은 가능할 것으로 보임
axis=(0, 1) 활용 예시
arr = np.arange(25).reshape(5, 5)
arr[4][4] = 100
print(arr)
print(f"스칼라 값: {np.mean(arr)}")
print(f"axis=0: {np.mean(arr, axis=(0, ))}")
print(f"axis=1: {np.mean(arr, axis=1)}")
print(f"axis=(0,1) {np.mean(arr, axis=(0, 1))}") # 먼저 row 방향(axis=0) 으로 평균을 내서 1차원 배열로 만든 후
# column 방향(axis=1)로 평균을 내서 스칼라 값을 도출하는 것으로 보임
- Color normalization을 위한 코드에서의 쓰임
import numpy as np
import torchvision.transforms as transforms
from torchvision import datasets
def get_mean_std(data_dir):
'''
이미지 정규화 시 성능 향상 , 평균과 표준편차로 정규화 실행
data_dir = 이미지 들어있는 폴더 path
'''
transform = transforms.Compose([
transforms.Resize((1024, 1024)),
transforms.ToTensor()
])
dataset = datasets.ImageFolder(os.path.join(f'./{data_dir}'), transform)
print("데이터 정보", dataset)
meanRGB = [np.mean(x.numpy(), axis=(1,2)) for x,_ in dataset]
stdRGB = [np.std(x.numpy(), axis=(1,2)) for x,_ in dataset]
meanR = np.mean([m[0] for m in meanRGB])
meanG = np.mean([m[1] for m in meanRGB])
meanB = np.mean([m[2] for m in meanRGB])
stdR = np.mean([s[0] for s in stdRGB])
stdG = np.mean([s[1] for s in stdRGB])
stdB = np.mean([s[2] for s in stdRGB])
print("평균",meanR, meanG, meanB)
print("표준편차",stdR, stdG, stdB)
# train data, test data 다르게 nomalization 적용하려면 data_dir 바꾸세요.
data_dir = "./train"
get_mean_std(data_dir)
- 위 방식처럼 axis=(1,2)로 접근하는것을 통해 width, height로 구성된 평면의 평균값(스칼라 값)을 구할 수 있다!
- 단 그렇게 구해진 평균값은 3채널짜리 (RGB 3채널 이므로 스칼라값이 R, G, B 3개 값으로 구성되어 있다.) 이므로 np.mean([m[0] for m in meanRGB])를 통해 최종 스칼라값을 구하는것을 확인할 수 있다.
- 자주 활용한다면 유틸리티가 굉장히 올라갈 듯 싶다.
PREVIOUS경제