분류에 쓰이는 머신러닝 알고리즘
- 베이즈통계와 생성 모델에 기반한 나이브 베이즈 (Naive Bayes)
- 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀 (Logistic Regression)
- 데이터 균일도에 따른 규칙 기반의 결정 트리 (Decision Tree)
- 개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 서포트 벡터 머신(Support Vector Machine)
- 근접 거리를 기준으로 하는 최소 근접 (Nearest Neighbor) 알고리즘
- 심층 연결 기반의 신경망 (Neural Network)
- 서로 다른(또는 같은) 머신러닝 알고리즘을 결합한 앙상블 (Ensemble) / 본 포스트는 앙상블에 초점을 둬서 정리해 봤습니다.
앙상블을 통한 분류
앙상블을 통한 분류 방식은 크게 3개로 나눌 수 있다.
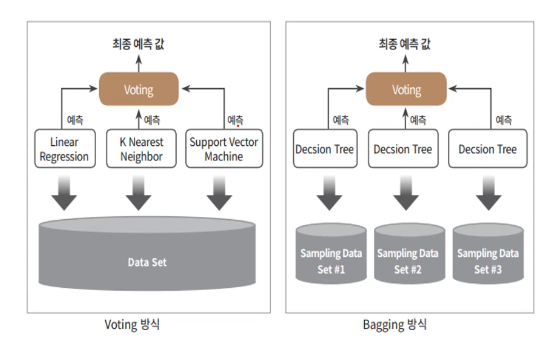
- 보팅(Voting): 전체 데이터에 대해 각각 다른 분류기를 사용하며 2가지 방식으로 나뉨
- 하드 보팅: 다수결 원칙 -> 다수의 분류기가 선택한 예측값을 최종 보팅 결과값으로 선정
- 소프트 보팅: 분류기들의 레이블 값 결정 확률을 모두 더하고 평균내서 가장 높은 확률을 가진 레이블을 최종 선정
- 배깅(Bagging): 부트스트래핑된 데이터(중복을 허용하며 일부 샘플링)에 대해 동일한 종류의 분류기를 사용하는 방식
- 대표적인 방식으로 랜덤 포레스트가 존재한다. 랜덤 포레스트에서 사용되는 분류기는 의사 결정 트리(Decision Tree)이다.
아래 그림을 보면 두 방식의 차이가 보다명확히 보일 것이다. 한가지 유의할 점으로 배깅 방식 역시 최종 label을 예측할 때는 투표(voting)를 진행한다. 보팅 방식, 배깅 방식으로 나눌 땐 데이터 셋이 전체가 한번에 쓰이는지, 부트스트래핑된 서브 데이터셋이 각 분류기에 쓰이는지와, 서로 같은 분류기를 쓰는지 다른분류기를 쓰는지 여부를 보면 될 듯 하다.
- 부스팅(Boosting): 여러 분류기가 순차적으로 학습하되, 앞에서 학습한 분류기의 예측이 틀린 데이터에 대해 올바르게 예측할 수 있도록 다음 분류기에 가중치를 부여하면서 학습과 예측을 진행하는 방식
- 대표적인 방식으로 Ada Boost, Gradient Boost, XGBoost, LightGBM (XGBoost, LightGBM은 Gradient Boost 기반임)이 존재한다.
- AdaBoost
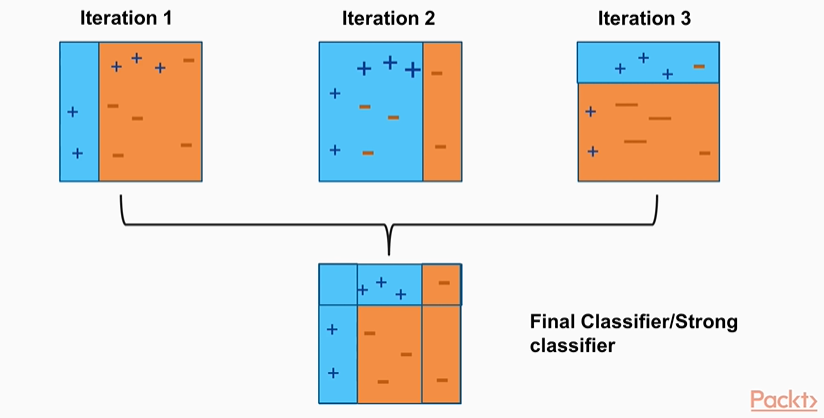
- 각 Iteration 마다 잘못 분류된 데이터들에 대해 가중치를 부여해서 다음 번 Iteration때 잘 분류할 수 있도록 가중치를 먹임
- 각 Iteration별로 가중치를 가지고 있어서 각 Iteration이 예측한것과 가중치를 조합해서 **최종 결과를 냄**
- Gradient Boost
- Ada Boost와 다른 부분은 가중치 업데이트를 경사하강법(Gradient Descent)를 이용하는것뿐임
- LightGBM
- Label이 불균형할 경우 boost_from_average=False 줘야함
- AdaBoost
- 대표적인 방식으로 Ada Boost, Gradient Boost, XGBoost, LightGBM (XGBoost, LightGBM은 Gradient Boost 기반임)이 존재한다.
결정 트리
앙상블 기법에서의 머신러닝 모델로 결정 트리를 자주 사용한다. 결정 트리의 알고리즘을 파악해보자.
- 결정 트리
- 깊이가 깊어질수록 과적합으로 이어지기 쉬워서 적은 깊이(적은 결정노드)로 높은 예측 정확도를 가지는 것을 목표로 해야함
- 최종적으로 분류된 데이터들의 정보 균일도가 높아야함
- 비슷한 애들끼리 잘 분류가 되어야 한다는 말
- 이를 판단할 수 있는 방법이 2가지 존재
- 정보 이득 지수
- 엔트로피 개념 기반
- 엔트로피는 주어진 데이터의 혼잡도 의미
- 서로 다른 값이 섞여 있으면 엔트로피 높음, 같은 값이 섞여 잇으면 낮음
- 수식
\(1 - 엔트로피 지수\)
- 엔트로피 개념 기반
- 지니 계수
- 0이 가장 평등, 1로 갈수록 불평등
- 지니 계수가 낮을수록 데이터 균일도가 높은 것
- 정보 이득 지수
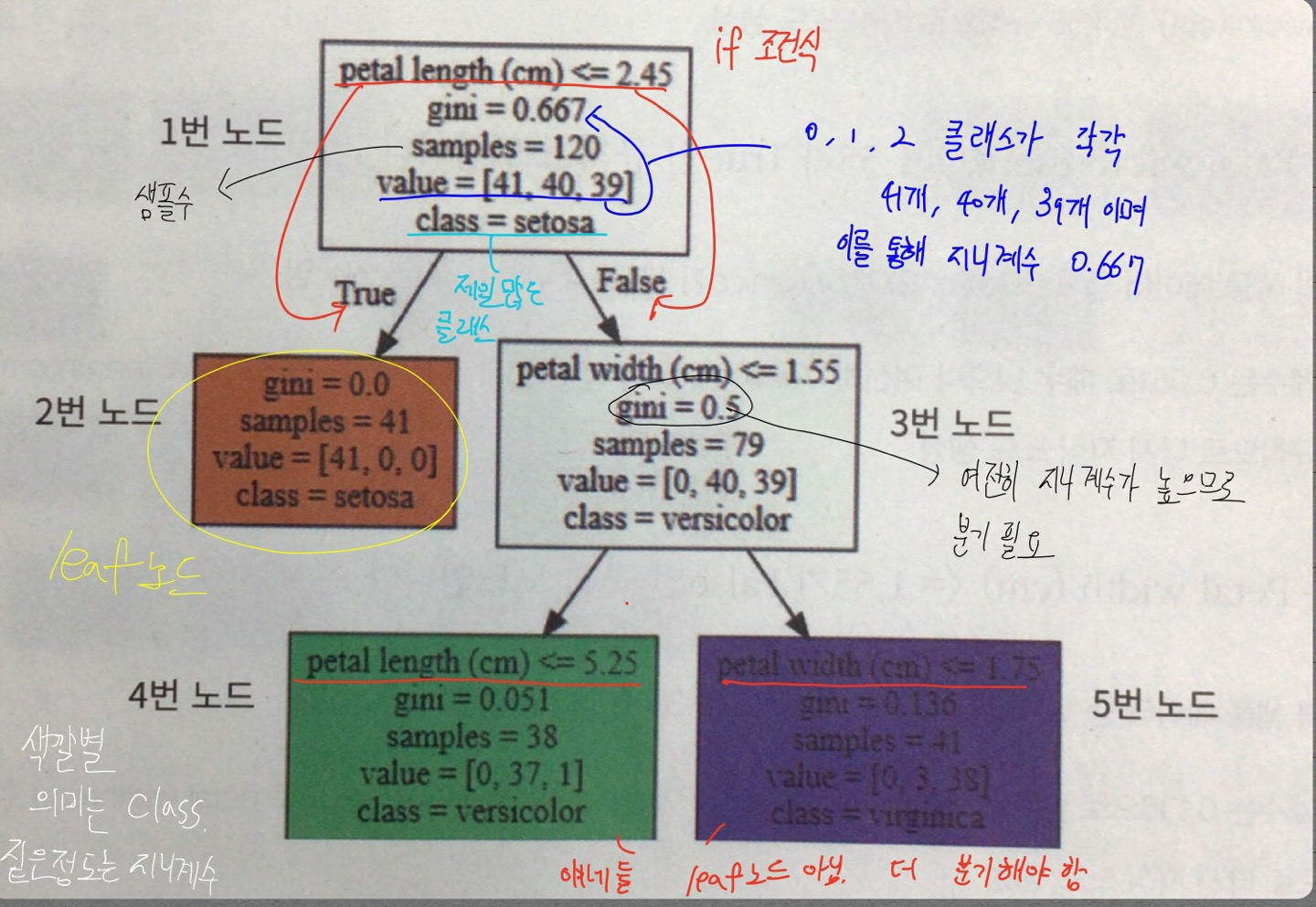
- 알고리즘 진행 과정
- 데이터 집합의 모든 아이템이 같은 분류에 속하는지 확인
- 만약 True면 -> 리프 노트도 만들어서 분류 결정
- 그렇지 않고 Else이면 -> 데이터 분할하는 데 가장 좋은 속성과 분할 기준을 찾음
- 해당 속성과 분할 기준으로 데이터 분할하여 branch 생성
- 재귀적으로 모든 데이터 집합의 분류가 결정될 때까지 수행
-
matplotlib 그래프 출력 예시
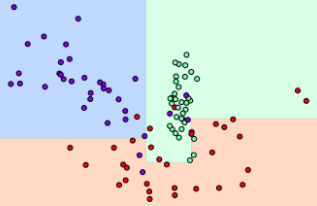
- x축(0 ~ 1) 기준으로 0.4정도 일 때 y(0 ~ 1)가 0.3이상이면 보라색, 미만이면 빨간색. 이런식으로 해서 쭉 가는거임
PREVIOUS경제