| 본 포스트는 데이터 전처리를 위해 pandas를 자유자재로 활용하기 위해 필요한 데이터 베이스 기본 지식들을 정리하려 한다. |
join
공통된 column에서 새로운 result table을 만들기 위함이다.
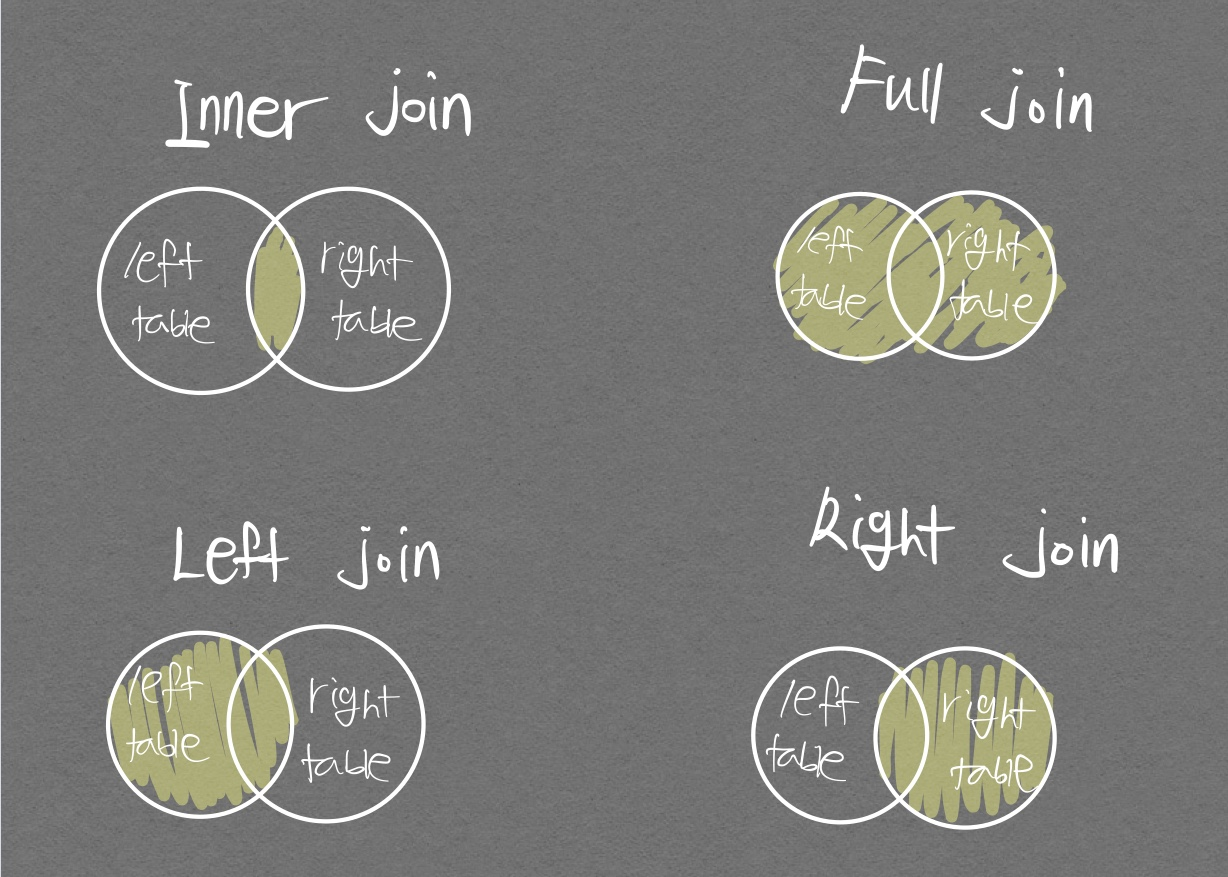
일반적으로 가장 많이 쓰는 join은 inner join으로 동일한 column에 대해 모든 데이터를 다 가져오는것이다.
아래의 적용 예시를 보자
import pandas as pd
import numpy as np
movies = pd.read_csv('./data/movies.csv')
ratings = pd.read_csv('./data/ratings.csv')
print(movies.shape, ratings.shape)
(9742, 3) (100836, 4)
movies.head()
| movieId | title | genres | |
|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
| 1 | 2 | Jumanji (1995) | Adventure|Children|Fantasy |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy |
ratings.head()
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 |
| 1 | 1 | 3 | 4.0 | 964981247 |
| 2 | 1 | 6 | 4.0 | 964982224 |
| 3 | 1 | 47 | 5.0 | 964983815 |
| 4 | 1 | 50 | 5.0 | 964982931 |
위 두 테이블은 movieId라는 공통 column을 가지고 있어서 join 연산자 사용이 가능하다.
# in_df = pd.merge(movies,ratings, left_on='movieId', right_on='movieId', how='inner')
in_df = pd.merge(movies, ratings, how='inner', on='movieId')
# in_df = movies.merge(ratings)
in_df
| movieId | title | genres | userId | rating | timestamp | |
|---|---|---|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy | 1 | 4.0 | 964982703 |
| 1 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy | 5 | 4.0 | 847434962 |
| 2 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy | 7 | 4.5 | 1106635946 |
| 3 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy | 15 | 2.5 | 1510577970 |
| 4 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy | 17 | 4.5 | 1305696483 |
| ... | ... | ... | ... | ... | ... | ... |
| 100831 | 193581 | Black Butler: Book of the Atlantic (2017) | Action|Animation|Comedy|Fantasy | 184 | 4.0 | 1537109082 |
| 100832 | 193583 | No Game No Life: Zero (2017) | Animation|Comedy|Fantasy | 184 | 3.5 | 1537109545 |
| 100833 | 193585 | Flint (2017) | Drama | 184 | 3.5 | 1537109805 |
| 100834 | 193587 | Bungo Stray Dogs: Dead Apple (2018) | Action|Animation | 184 | 3.5 | 1537110021 |
| 100835 | 193609 | Andrew Dice Clay: Dice Rules (1991) | Comedy | 331 | 4.0 | 1537157606 |
100836 rows × 6 columns
위 결과를 보고 다음과 같은 생각이 들었다.
아니.. 공통된 데이터만 뽑으려 inner join을 사용하고, 사이즈가 작은 테이블은 데이터 갯수가 9700개 밖에 안되는데 공통된 데이터가 100836개나 된다고..?
나와 같은 생각을 한 사람이 있다면 형광펜 부분을 주의깊게 생각해보자. 아래 코드를 보면 이해가 쉬울 것이다.
df1 = pd.DataFrame({'a': ['foo', 'bar', 'baz'], 'b': [1, 2, 3]})
df1
| a | b | |
|---|---|---|
| 0 | foo | 1 |
| 1 | bar | 2 |
| 2 | baz | 3 |
df2 = pd.DataFrame({'a': ['foo','bar','foo','foo','foo'], 'c':[75,25,52,67,7373]})
df2
| a | c | |
|---|---|---|
| 0 | foo | 75 |
| 1 | bar | 25 |
| 2 | foo | 52 |
| 3 | foo | 67 |
| 4 | foo | 7373 |
pd.merge(df1, df2, how='inner', on='a')
| a | b | c | |
|---|---|---|---|
| 0 | foo | 1 | 75 |
| 1 | foo | 1 | 52 |
| 2 | foo | 1 | 67 |
| 3 | foo | 1 | 7373 |
| 4 | bar | 2 | 25 |
df1 데이터의 갯수는 3개여서 , inner join 하면 데이터 갯수가 최대 3개가 나와야 할 것 같지만!
result table의 데이터 갯수는 5개가 되었다.
on 인자의 column을 기준으로 같은 데이터(여기서는 foo)를 두 테이블에서 모조리 가져오기 때문이다.
즉 df1의 foo 갯수: 2개, df2의 foo 갯수: 3개여서 총 5개의 데이터가 result table에 생기게 된다.
PREVIOUS경제