Abstract
- X-ray의 위험성이 크기 때문에 low-dose한 CT 이미지의 노이즈 제거가 굉장히 주목되는 이슈임.
- 딥러닝의 발전으로 많은 부분에서 노이즈 제거가 진보를 이루었지만 Low-dose CT(LDCT) 이미 지에 대해서는 다음과 같은 카테고리에서 부족한 부분이 있다.
- 낮은 노이즈 제거 효율성
- over-smoothed 문제
- 본 논문에서는 Edge enhancement based Densely connected Convolutional Neural Network(EDCNN)을 제안하며 그 구조는 아래와 같다.
- 최신의 학습 가능한 Sobel 컨볼루션 연산
- MSE, perceptual loss를 합친 compound loss
Introduction
CT 이미지는 현대 의학의 질병 진단을 위한 핵심적 데이터지만 선명한 X-ray 사진 이미지를 얻기 위해 방사선 노출량을 늘리면 그만큼 잠재적인 위험요소도 커지기 때문에 low-dose한 CT 이미지를 통해 진단을 하는것이 중요한 이슈임.
CNN 기반의 이미지 제거를 위한 다양한 모델(Encoder-Decoder with residual block or conveying paths, fully connetected networks, 3D 정보 활용하는 모델)이 존재하지만 over-smootehd, 가장자리 정보 손실, 자세한 정보 손실 등의 단점이 해결되지 않고 있다.
- 따라서 본 논문에서는 Edge enhancement based Densely connected Convolutional Neural Network(EDCNN)을 제안하며 그 특징은 다음과 같다.
- 학습 가능한 Sobel 컨볼루션 연산 기반의 Edge enhancement 모듈 사용
- 최적화 작업중 순응적인 특징 추출이 가능
- Densely connected FCN 활용
- Densely connected 의미
- ResNet의 Shortcut 개념이 확장된 것이다. ResNet은 Feature map 끼리 summation 한 것이라면, Densely connected FCN은 Feature map 끼리 Concat(결합)한다
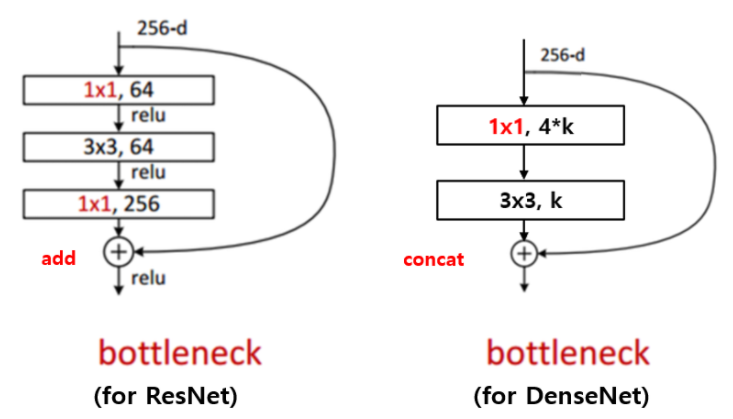
- Densely connected 의미
- MSE loss, multi-scales perceptual loss를 합친 Loss 제안
- 학습 가능한 Sobel 컨볼루션 연산 기반의 Edge enhancement 모듈 사용
Related Work
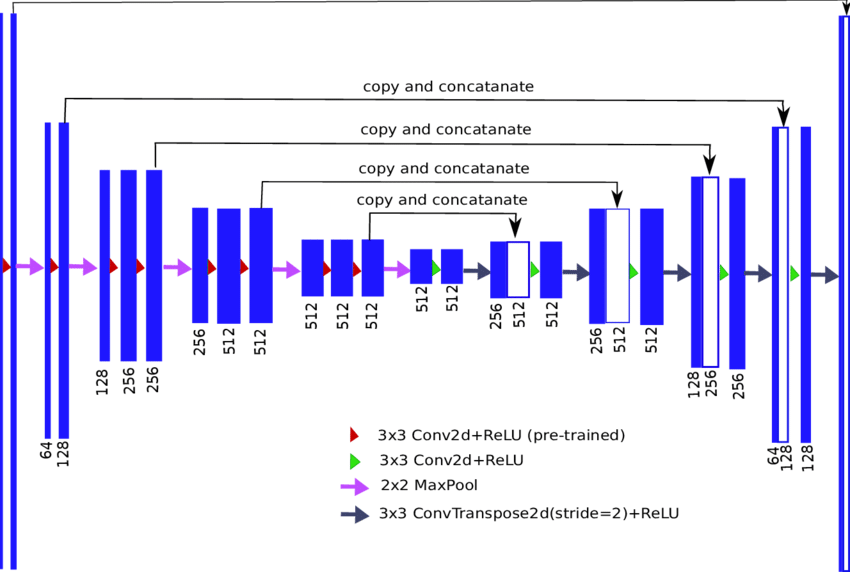
Encoder-Decoder
-
대칭적 구조를 사용하는 모델
-
Skip connection을 사용함
- Skip connection이란 위 encoder-decoder 그림에서 볼 수 있듯 몇개 layer를 건너 뛰면서 feature를 전달하는 것인데, 이러한 작업을 통해 gradient-vanishing을 해결할 수 있는 지름길(shortcut)을 제공하거나, 너무 추상화된 정보를 복원하는데 도움을 주는것에 사용된다.
Fully convolution network
- 모든 layer가 convolution layer로 이루어져 있는 경우를 의미함
- 제안하는 EDCNN 모델이 FCN 기반임
GAN-based Algorithms
- 판별자, 생성자가 적대적으로 학습을 진행하며, 판별자는 high-dose CT 이미지와, 생성자로 인해 노이즈가 제거된 CT 이미지를 구분하게 하고, 생성자는 판별자는 속일 수 있도록 학습된다.
Loss Function
Per-pixel Loss
- High-dose CT 이미지와 픽셀별로 값을 비교하여 MSE 값을 loss로 사용하는 것이지만 이미지의 노이즈 제거 작업에 필요한 이미지 구조 정보(structure information)를 담지 못한다
- 이미지에서의 구조 정보란 조명에 독립적인 속성이며, 이미지 구조 정보를 담기 위해선 luminance, contrast가 제거되어야 한다고 함 (출처)
Perceptual Loss
- 이미지 변환에서 공간 정보 의존성 문제 해결을 위한 Loss
- 이미지를 Feature space로 변환 이후 바로 유사도 비교를 진행하는 Loss 이지만 cross-hatch artifact 와 같은 문제점 존재
Other Loss
- Gan 모델에 활용하는 Loss들은 Adversarial loss를 사용하며, 그 외에 MAP-NN 모델에서는 adversarial loss + MSE loss + Edge incoherence
Methodology
Edge enhancement Module
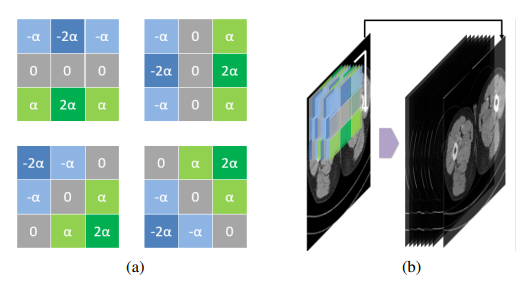
- 그림에서 볼 수 있듯 학습 가능한 Sobel filter 사용
- 수직, 수평, 대각방향을 모두 고려한 4가지 타입의 필터를 하나의 Group으로 사용
- 학습을 통해 점점 Edge Information을 잘 찾게됨
Overall Network Architecture
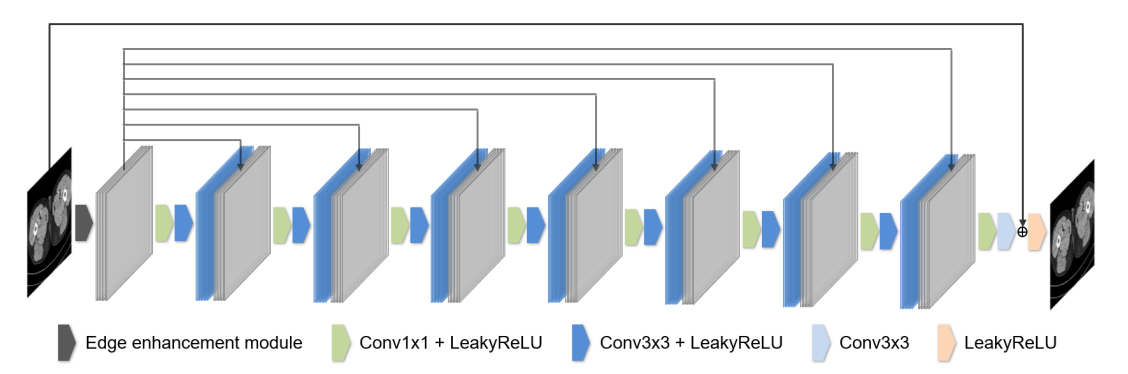
- 제안하는 EDCNN 구조 그림
- 1개의 Edge enhancement module
- 8개의 컨볼루션 레이어
- DenseNet의 Dense connection을 적용하여 위 그림에서 회색 피처맵들이 각각의 다른층 피처맵들과 결합(Concat)되는것을 확인할 수 있음
- 이를 통해 Sobel filter를 통해 추출된 Edge 정보를 각 layer에서 학습하는데 사용할 수 있으며, 가장 마지막 layer에서 이미지 원본 영상 정보를 학습하는데 사용함
- 마지막 Layer의 convolution filter 개수를 1로 맞춰서(1채널) 원본 이미지와 summation이 가능하게함
- 이것을 통해 noise-denoised 이미지(2채널)를 얻어서 직접적으로 noise 분포나 복원 정보를 학습할 수 있다고 하는데, 내 생각에 noise가 들어있는 원본을 직접 pixel-wise로 더했으므로 noise 분포를 그대로 가져오고, 두 이미지간의 차이등을 통해 복원 정보를 파악할 수 있지 않나 싶다
Compound Loss Function
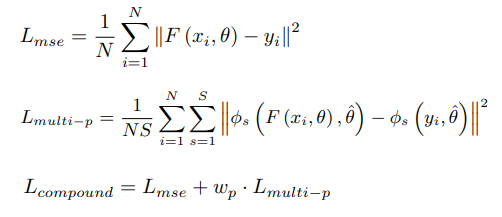
- 위 그림에서 알 수 있듯 두가지 Loss(MSE, Multi-scales perceptual loss)를 합친 Loss를 활용함.
- Perceptual Loss는 perceptual similarity를 측정하기 위한 Loss이며 식은 다음과 같다.
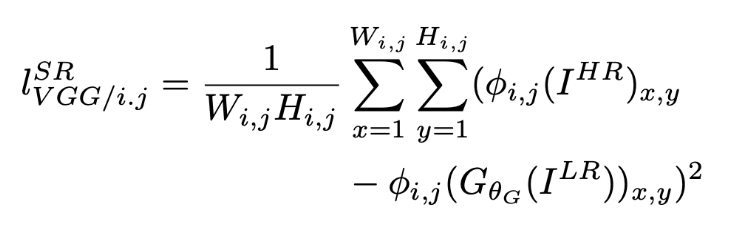
- 위 식은 pre-trained된 VGGnet을 이용해서 j번째 convolution에 의해 얻어진 Featuremap과의 L2 Norm을 구한다
- pixel 각각의 값이 아닌
Perceptual Similarity에 집중하였기 때문에 좀 더 Detail한 부분을 잘 잡아낼 수 있다고 한다 - 본 논문에서는 VGGnet이 아닌 Resnet50(ImageNet으로 사전학습 된)의 Featuremap을 적용한다
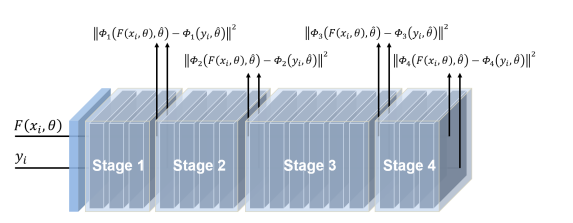
- multi-scales perceptual loss 그림이며, 각 stage에서 나온 Featuremap들의 similarity를 비교하므로써 4개의 perceptual loss를 구하고, 이를 평균낸 값이 바로 multi-scales perceptual loss 값이다
Experiments and Results
Dataset
- 2016 NIH AAPM-Mayo Clinic Low-Dose CT Grand Challenge 데이터셋 사용 (출처: https://www.nature.com/articles/s41597-021-00893-z.pdf)
- Low dose CT 이미지, Normal dose CT 이미지들을 10명의 환자한테서 얻은 데이터
- 512x512
Experimental Setup
- Weight Initilization은 랜덤하게 초기화
- Sobel Factor의 $\alpha = 1$
- Compound Loss의 하이퍼 파라미터 $w_p = 0.01$
- AdamW optimizer 사용
- $lr = 0.001, 200 epoch$
Results
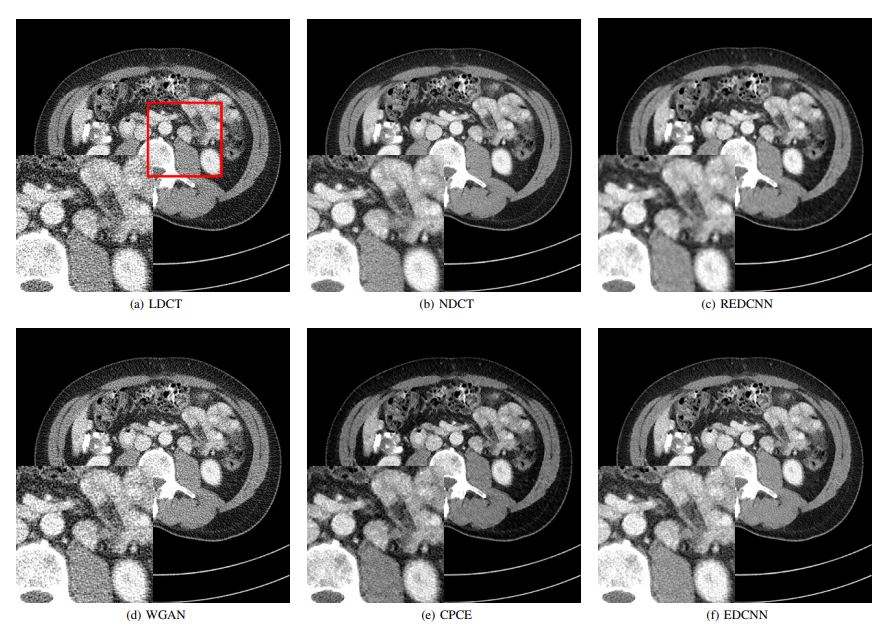
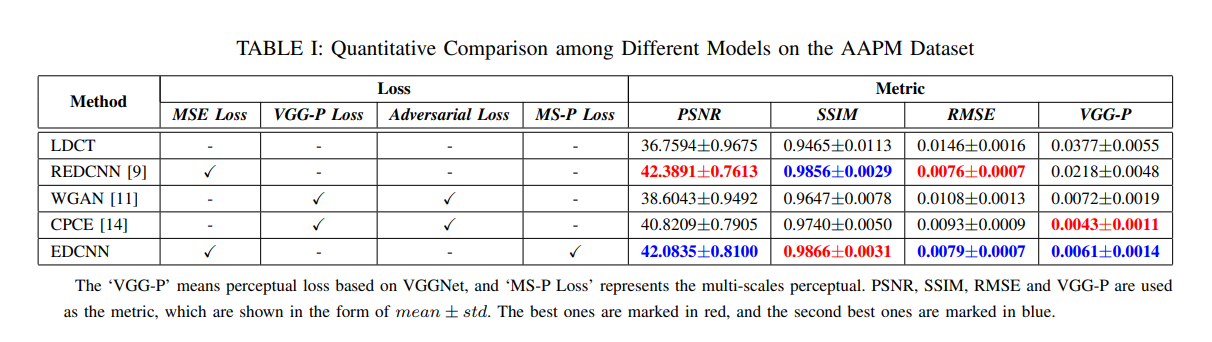
- Noise 제거 metric에는 크게 3가지가 존재한다
- Peak Signal to Noise Ratio(PSNR)
- Structural SIMilarity(SSIM)
- Root Mean Square Error(RMSE)
- VGG-P(VggNet19 perceptual loss)
- 본 논문에서 추가적인 비교를 위해 사용한 loss
- 가장 높은 값이 빨간색, 두번째로 높은 값이 파란색이다
- EDCNN이 best or subpotimal result를 모든 평가기준에서 달성하여 픽셀별 성능, 구조에 관한 성능이 밸런스를 이루었다
- RMSE, PSNR은 MSE와 관련된 Metric이여서 학습과정에서 MSE Loss가 사용된 REDCNN, EDCNN 모델이 성능이 좋음을 알 수 있다. 하지만 이것이 Visual quality와 직관적인 관련이 있는것은 아니다. (영상처리 수업시간에도 교수님께서 예시를 들어주신 부분이며, PSNR 값이 높아도 sharpness, detail information 등이 낮아서 visual quality가 좋지 않은 경우가 발생할 수 있음)
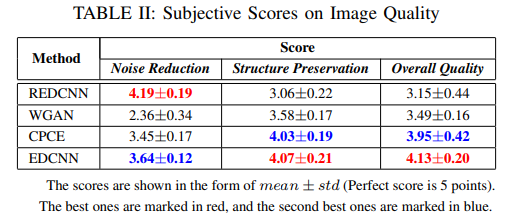
- 위 테이블은 20개의 그룹이 각각 6개의 노이즈 제거된 이미지를 가지고 평가한 점수이다. 내 생각에 visual quality는 사람이 느끼는 부분이기에 사람이 직접 점수를 매기는 방식으로 한것으로 보인다.
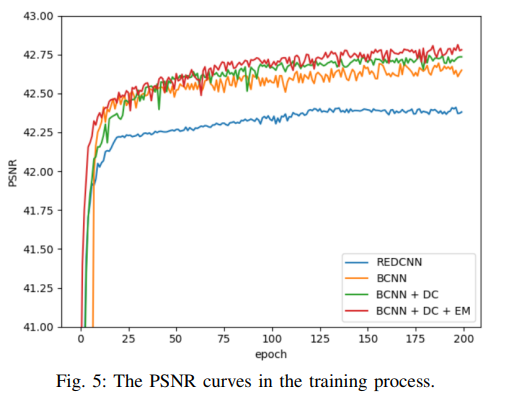
- BCNN (Edge enhancement module, dense connection 제외)
- BCNN + DC (Edge enhancement Module 제외)
- BCNN + DC + EM
- 한가지 재미있는 부분은 Basic CNN 모델로 PSNR 점수에 관해서 REDCNN 모델을 이긴다는 것
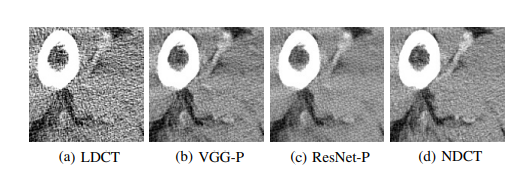
- 위 그림은 (a) 이미지를 입력으로 받았을 때 (b)VGG perceptual Loss를 사용한 것과 (c)Resnet perceptual Loss를 사용한 것을 보여주는것인데, 한눈에 보기에도 visual quality 면에서 (c)의 Noise가 (b)보다 적다
Conclusion
- 본 논문은 Dense-Net의 Densely connected convolutional 구조, 학습 가능한 Sobel 필터, Compound Loss를 mayo 데이터셋을 활용하여 을 PSNR, SSIM, RMSE, VGG-P 뿐 아니라 사람이 관여해서 직접 평가한 metric 까지 포함하여 다양한 실험을 진행하였으며, 이러한 작업을 통해 효과적인 노이즈 제거를 할 수 있었음을 입증하였다.
PREVIOUS경제