- Series는 칼럼이 한개 / DataFrame은 칼럼이 여러개
Series
- Key, value 형태로 이루어져 있음. Dict타입과 호환 가능
- 리스트와도 호환가능. 이때는 정수형 인덱스가 들어감
- 인덱스 종류
-
정수형 인덱스
sr[0], sr[0:2] -
인덱스 이름
sr['c'], sr['c': 'e']
-
DataFrame
- 각 행이 ‘record’라고 불리며, 각 열이 ‘feature’라고 불림
초기 정보 보는법
DataFrame.info()
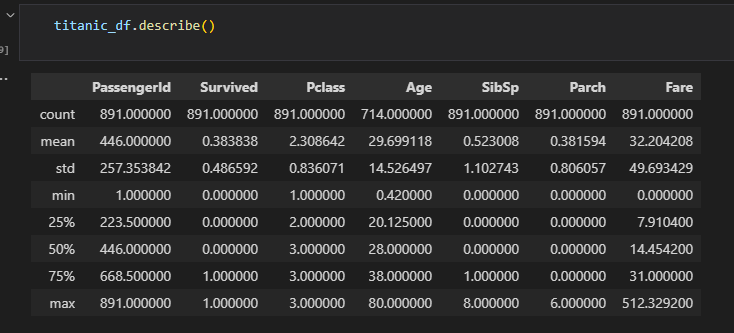
DataFrame.describe() # 숫자형 칼럼(int, float)에 대해서만 계산하며 object는 자동으로 제외시킨다
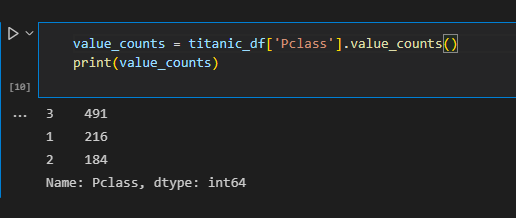
DataFrame['column_name'].value_counts() # Series로 반환시킨 데이터에 대해 특정 값이 몇번 나오는지를 알 수 있게 해줌. 즉 데이터 분포도 파악이 가능한 좋은 함수

-
DataFrame → Dict 형태로의 변환
# DataFrame을 딕셔너리로 변환 dict3 = df_dict.to_dict('list') # 이런식으로 'list'를 인자로 주면 훨씬 깔끔하다 print('\n df_dict.to_dict() 타입:', type(dict3)) print(dict3) dict3 = df_dict.to_dict() print('\n df_dict.to_dict() 타입:', type(dict3)) print(dict3)df_dict.to_dict() 타입: <class 'dict'> {'col1': [1, 11], 'col2': [2, 22], 'col3': [3, 33]} df_dict.to_dict() 타입: <class 'dict'> {'col1': {0: 1, 1: 11}, 'col2': {0: 2, 1: 22}, 'col3': {0: 3, 1: 33}}
인덱싱
-
Numpy와 달리 [ ]에 0, 1과 같은 값을 넣을 경우 에러 발생.
칼럼명을 넣어줘야함print('단일 컬럼 데이터 추출:\n', titanic_df[ 'Pclass' ].head(3)) print('\n여러 컬럼들의 데이터 추출:\n', titanic_df[ ['Survived', 'Pclass'] ].head(3)) print('[ ] 안에 숫자 index는 KeyError 오류 발생:\n', titanic_df[0])output 단일 컬럼 데이터 추출: 0 3 1 1 2 3 Name: Pclass, dtype: int64 여러 컬럼들의 데이터 추출: Survived Pclass 0 0 3 1 1 1 2 1 3 KeyError: 0 -
슬라이싱은 가능
titanic_df[0:2]PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr.... male 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mr... female 38.0 1 0 PC 17599 71.2833 C85 C -
인덱싱 방식은 위치(Position)기반 인덱싱, 명칭(Label)기반 인덱싱이 있으며 그냥 DataFrame[ ]과 같은 형식으로 데이터 접근이 가능하지만 내 생각에 위치기반 인덱싱, 명칭 기반 인덱싱을 명확히 구분하게 하기 위해서 iloc, loc 방식을 사용하는것으로 보임
위치 기반 인덱싱
- iloc (Integer - location): 위치 기반 인덱싱
- 0 부터 시작하는 행, 열의 위치 좌표에만 의존함
- 앞부분이 행 조절, 뒷부분이 열 조절
data_df_reset.iloc[0, 1] # 0이 행조절, 1이 열조절. # 즉 첫번째 행의 두번째 열 값이 튀어나옴Chulmin
명칭 기반 인덱싱
- loc (label - location): 명칭 기반 인덱싱
- 인덱스, 칼럼명으로 접근 ⇒ 행 위치에
DataFrame 인덱스, 열 위치에칼럼명- 행 위치같은 경우 불린 인덱싱 지원을 위해 시리즈타입은 호환이 됨 (간단 테스트로 정수형 Series 넣으니까 접근 됐음. 아마 DataFrame.index를 정수가 아니라 문자열 같은걸로 변경하고 다시 실행하면 문자형은 못찾음)
- 명칭 기반 인덱싱은 DataFrame.index 객체 (정확히는 pandas.core.indexes.range.RangeIndex)에서 값을 찾음
- 명칭 기반 인덱싱은 슬라이싱 할 때 종료 값을 포함한 범위가 반환됨. 위치기반 인덱싱과 혼돈될 수 있는 부분이여서
매우 조심해야함 - 행 위치에 DataFrame
data_df.loc['one', 'Name'] data_df_reset.loc[1, 'Name'] # 이런식으로 index가 정수형일 경우엔 정수 입력 가능. 명칭 기반이라고 해서 숫자만 써야하는것 아님 # data_df_reset 데이터프레임은 reset_index를 통해 1부터 인덱스가 시작되도록 변경해놓은 데이터프레임이여서 첫번째 줄의 Name 칼럼 값이 나옴Chulmin Chulminprint('명칭기반 ix slicing\n', data_df.ix['one':'two', 'Name'],'\n') print('위치기반 iloc slicing\n', data_df.iloc[0:1, 0],'\n') print('명칭기반 loc slicing\n', data_df.loc['one':'two', 'Name'])명칭기반 ix slicing one Chulmin two Eunkyung Name: Name, dtype: object 위치기반 iloc slicing one Chulmin Name: Name, dtype: object 명칭기반 loc slicing one Chulmin two Eunkyung Name: Name, dtype: object - 인덱스, 칼럼명으로 접근 ⇒ 행 위치에
불린 인덱싱(중요)
불린 인덱싱을 통해 조건문을 활용하여 특정 값을 가져오거나, 일정 범위의 값을 가져오는등의 고급 테크닉이 가능하다.
- loc로 생각해보면 인덱스, 칼럼명을 입력해줘야 하는데 칼럼명은 생략했으니 모든 칼럼을 출력, 인덱스의 경우 Boolean type을 가지고 있는 Series도 호환이 가능하다
- iloc은 불린 인덱싱 지원 X
- and, or, not 조건 연산자를 활용해서 응용 가능
hj_list = []
for i in range(891):
if i == 460:
hj_list.append(True)
else:
hj_list.append(False)
hj_list = np.array(hj_list)
hj_list = pd.Series(hj_list)
titanic_df[hj_list], titanic_df.loc[hj_list]
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
460 461 1 1 Anderson, M... male 48.0 0 0 19952 26.55 E12 S
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
460 461 1 1 Anderson, M... male 48.0 0 0 19952 26.55 E12 S
titanic_df[ (titanic_df['Age'] > 60) & (titanic_df['Pclass']==1) & (titanic_df['Sex']=='female')]
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
275 276 1 1 Andrews, Mi... female 63.0 1 0 13502 77.9583 D7 S
829 830 1 1 Stone, Mrs.... female 62.0 0 0 113572 80.0000 B28 NaN
- 예시를 통한 이해
label = train_df.loc[train_df['file_name'] == img_path]['label']- train_df.loc 이므로 [ ] 안에서는 ,를 기준으로 앞쪽은 DataFrame 인덱스, 뒤쪽은 칼럼명을 넣어준다.
- ,가 없으므로 칼럼명은 비어있는것으로 간주하여 해당하는 record(모든 칼럼을 다 가져오므로)를 가져오는것이 된다.
- train_df[‘file_name’]을 통해 Series 타입으로 전체 데이터 중 ‘file_name’ 쪽 데이터만 가져오고, 이어서 조건연산자를 통해 [False, False, … , True, False] 형태의 Series 타입 데이터로 변형시켜 불리언 인덱싱으로 특정 행을 가져오도록 한다.
- 그렇게 가져온 데이터(record)들 중 ‘label’ 칼럼의 데이터들만 가져오게 된다.
iloc, loc 등을 사용하지 않고 바로 df['column name'] 으로 접근하는 것은 전체 record를 가져오되 (행 인덱스가 명시되어있지 않으므로), column name에 따라서 filtering 해서 가져오는것으로 생각하면 될 듯 하다.
new_df[['name', 'price']]
삭제, 삽입
- column명 지정 삭제. axis=1 같은 경우는 행 방향으로 ‘Class’라는 이름을 가진 column을 찾겠다
df_copy.drop(['Time','Amount'], axis=1, inplace=True) - index 접근을 통한 행 삭제.
- 하나의 index는 하나의 record(데이터 한 행)를 가리킴
def get_outlier(df=None, column=None, weight=1.5): # fraud에 해당하는 column 데이터만 추출, 1/4 분위와 3/4 분위 지점을 np.percentile로 구함. fraud = df[df['Class']==1][column] quantile_25 = np.percentile(fraud.values, 25) quantile_75 = np.percentile(fraud.values, 75) # IQR을 구하고, IQR에 1.5를 곱하여 최대값과 최소값 지점 구함. iqr = quantile_75 - quantile_25 iqr_weight = iqr * weight lowest_val = quantile_25 - iqr_weight highest_val = quantile_75 + iqr_weight # 최대값 보다 크거나, 최소값 보다 작은 값을 아웃라이어로 설정하고 DataFrame index 반환. outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index return outlier_index outlier_index = get_outlier(df=df_copy, column='V14', weight=1.5) # 위 함수는 약간 번외임. 이상치로 판정된 DataFrame.index를 return 한다는 것에 주목 df_copy.drop(outlier_index, axis=0, inplace=True) # axis=0임에 주목. axis=0 방향으로 내려가면서 받은 index 값을 찾고 그 index가 가리키는 데이터(record)를 지운다
- 하나의 index는 하나의 record(데이터 한 행)를 가리킴
groupby( ) 적용
- by 인자에 지정한 칼럼명을 기준으로 삼음
-
Aggregation 함수와 연계 가능하며 이중 count( )를 사용한것을 예로들면 Pclass가 1일때 각 칼럼별로 몇개씩 있는건지 테이블로 나옴
titanic_groupby = titanic_df.groupby(by='Pclass') titanic_groupby.count() '''output PassengerId Survived Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Pclass 1 216 216 216 216 186 216 216 216 216 176 214 2 184 184 184 184 173 184 184 184 184 16 184 3 491 491 491 491 355 491 491 491 491 12 491 ''' -
여러개의 Aggregation과 연계 가능하며 .agg( ) 를 사용해야함
titanic_df.groupby('Pclass')['Age'].agg([max, min]) '''output max min Pclass 1 80.0 0.92 2 70.0 0.67 3 74.0 0.42 ''' -
여러개의 칼럼에 대해 여러개의 Aggregation을 적용하려면 Dict 형태로 사용한다
agg_format={'Age':'max', 'SibSp':'sum', 'Fare':'mean'} titanic_df.groupby('Pclass').agg(agg_format) '''output Age SibSp Fare Pclass 1 80.0 90 84.154687 2 70.0 74 20.662183 3 74.0 302 13.675550 ''' - 중복값 알아보기
-
value_counts()함수를 통해 gmm_cluster column의 다른 값들이 target값 기준으로 얼마나 있는지 알 수 있다
iris_result = irisDF.groupby(['target'])['gmm_cluster'].value_counts() print(iris_result)target gmm_cluster 0 0 50 1 2 45 1 5 2 1 50 Name: gmm_cluster, dtype: int64
-
조건에 따라서 값 변경시키기
- apply lambda식 사용
- lambda란?
- 함수의 선언과 함수내의 처리를 한 줄의 식으로 쉽게 변환하는 것
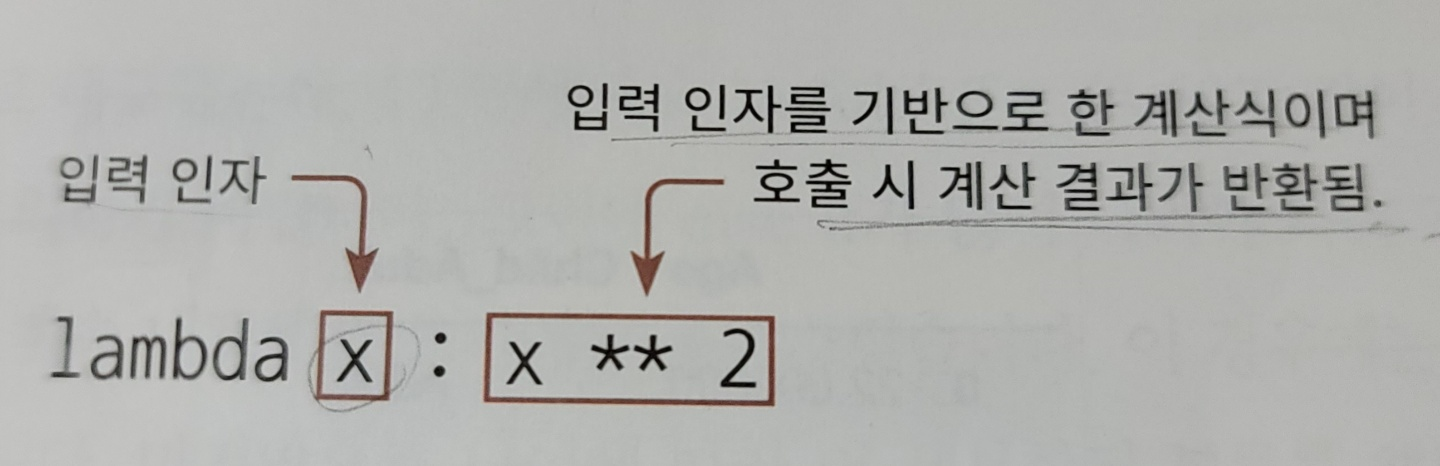
def get_square(a): return a**2 print('3의 제곱은:',get_square(3)) '''output 3의 제곱은: 9 ''' ## 람다 적용 후 lambda_square = lambda x : x ** 2 print('3의 제곱은:',lambda_square(3)) '''output 3의 제곱은: 9 '''- 입력 인자를 하나가 아니라 여러개로 받고 싶다면?
map( )함수 사용- map( )은 리스트의 요소들을 지정한 함수로 처리할 수 있게끔 해줌
-
1, 2, 3을 입력인자로 받아서 지정한 함수(여기서는 lambda x: x**2) 로 처리
a=[1,2,3] squares = map(lambda x : x**2, a) list(squares)
- DataFrame에서는 map이 아닌 apply를 사용 (로직은 거의 흡사함)
-
다른 부분은 map(‘함수’, ‘리스트’ ) 에서 ‘리스트’가 입력인자로 지정되는 것이였다면 apply에는 따로 입력인자로 지정할 것이 없음. DataFrame의 칼럼값이 입력인자로 바로 들어감
titanic_df['Name_len']= titanic_df['Name'].apply(lambda x : len(x)) titanic_df[['Name','Name_len']].head(3) '''output Name Name_len 0 Braund, Mr.... 23 1 Cumings, Mr... 51 2 Heikkinen, ... 22 '''
-
lambda는 if, else를 지원
- lambda 식 ‘ : ‘ 의 오른편에는 반환 값이 있어야 하기 때문에 조금 독특한 구조를 띔
-
else if를 지원하지 않기 때문에 붙는 조건이 많다면 아예 따로 함수를 지정해주는게 좋음
titanic_df['Child_Adult'] = titanic_df['Age'].apply(lambda x : 'Child' if x <=15 else 'Adult' ) titanic_df[['Age','Child_Adult']].head(8) '''output Age Child_Adult 0 22.000000 Adult 1 38.000000 Adult 2 26.000000 Adult 3 35.000000 Adult 4 35.000000 Adult 5 29.699118 Adult 6 54.000000 Adult 7 2.000000 Child ''' titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x : 'Child' if x<=15 else ('Adult' if x <= 60 else # ( ) 열고 else if 를 처리한 모습 'Elderly')) titanic_df['Age_cat'].value_counts() '''output Adult 786 Child 83 Elderly 22 Name: Age_cat, dtype: int64 ''' # 나이에 따라 세분화된 분류를 수행하는 함수 생성. def get_category(age): cat = '' if age <= 5: cat = 'Baby' elif age <= 12: cat = 'Child' elif age <= 18: cat = 'Teenager' elif age <= 25: cat = 'Student' elif age <= 35: cat = 'Young Adult' elif age <= 60: cat = 'Adult' else : cat = 'Elderly' return cat # lambda 식에 위에서 생성한 get_category( ) 함수를 반환값으로 지정. # get_category(X)는 입력값으로 ‘Age’ 컬럼 값을 받아서 해당하는 cat 반환 titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x : get_category(x)) titanic_df[['Age','Age_cat']].head() '''output Age Age_cat 0 22.0 Student 1 38.0 Adult 2 26.0 Young Adult 3 35.0 Young Adult 4 35.0 Young Adult '''
-
- lambda란?
Jupyter에서 DataFrame 볼 때 생략되는것 없이 다 보는 법
import pandas as pd
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
Null값 삭제 혹은 대체
# Null 이 너무 많은 컬럼들과 불필요한 컬럼 삭제
house_df.drop(['Id','PoolQC' , 'MiscFeature', 'Alley', 'Fence','FireplaceQu'], axis=1 , inplace=True)
# Drop 하지 않는 숫자형 Null컬럼들은 평균값으로 대체
house_df.fillna(house_df.mean(),inplace=True)