| 본 포스트는 Pandas로 대표 목적을 이루는데 있어서 필요했던 다른 문법들, 발생한 상황들, 생각들을 연결되게 정리하였다. 데이터를 다루다보면 의도치 않은 상황들을 자주 만나게 될텐데 그런 점을 대비하기 위함이다. |
list, dictionary 등이 string 으로 csv 파일에 저장되어 있을 때
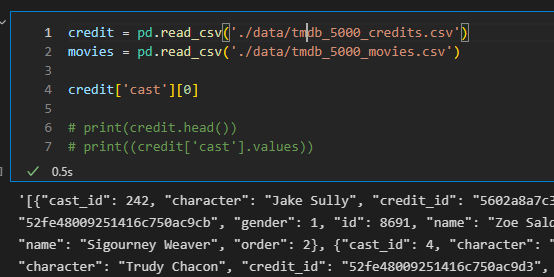
위 그림과 같이 csv를 읽어와서 데이터에 접근했는데 데이터가 string type으로 되어 있으면 난감하다..
이미 list, dict 형태를 갖추고 있지만 string 형식으로 저장되어 있는 데이터의 경우 ast 라이브러리를 사용하면 편하다.
import ast
x = '["a", "b", "c", " d"]'
x = ast.literal_eval(x)
x = [n.strip() for n in x]
x
['a', 'b', 'c', 'd']
Boolean indexing 에러 날 때
- DataFrame의 index값이 올바르게 되어있는지 check
- 가령 데이터가 100개이고, label은 0, 1인 numpy로 이루어져 있다고 하자. 이때 데이터의 인덱스가 150 같은 숫자가 들어가있다면 boolean indexing 할 때 에러남
DataFrame 값 대치할 때
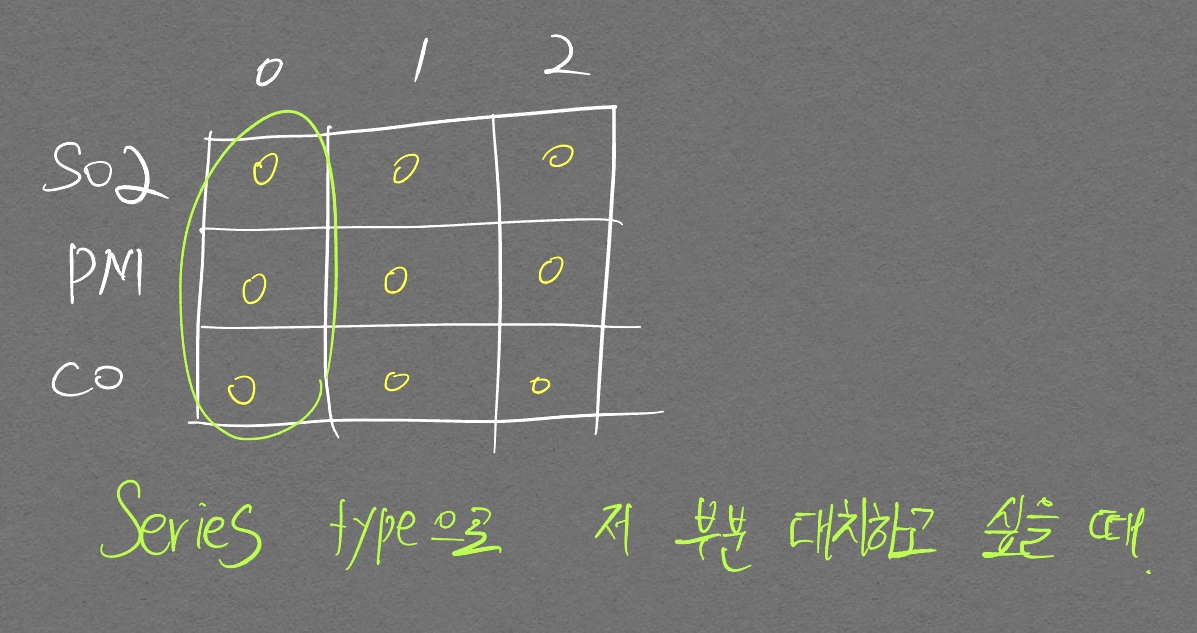
default index값이 아닌 dataFrame의 일부를 변경해야 한다고 하자.
핵심은 index, column을 모두 일치시켜야 한다는 것이다.
dt = pd.DataFrame(index=['SO2', 'PM', 'CO'], data=[[0] * 3 for _ in range(3)])
dt[0]
SO2 0
PM 0
CO 0
Name: 0, dtype: int64
위 Series 데이터에 대해서 5씩 더해주겠다고 생각한 다음 단순하게 아래와 같이 Series 객체를 더해줘보자
pd.Series([5, 5, 5]) + dt[0]
0 NaN
1 NaN
2 NaN
CO NaN
PM NaN
SO2 NaN
dtype: float64
바로 멸망한다. 위 결과처럼 나온 이유는 2개의 Series 객체가 가지고 있는 index가 일치 되는게 없어서 제대로 처리를 못해 Nan값으로 대치되어 있는 것이다.
pd.Series([5, 5, 5], index=['SO2', 'PM', 'CO']) + dt[0]
SO2 5
PM 5
CO 5
dtype: int64
위와 같이 index를 맞춰줘야 한다.
PREVIOUS경제