Abstract
- 최신 기술, 기술들의 장단점, 현재의 압축 모델의 정확도를 여러 프레임워크에서 보고, 모델 압축을 위한 가이드를 제공할 것임
Introduction
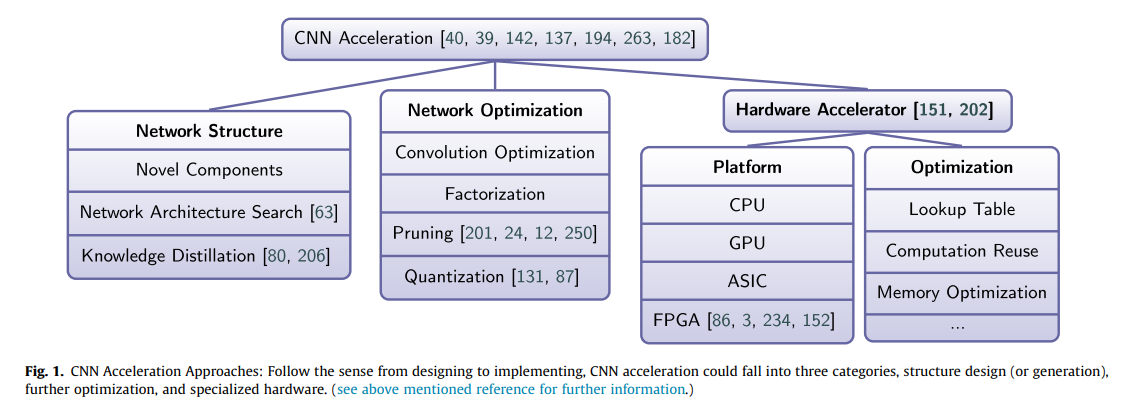
- Novel Components
- separable convolution, inception blocks, residual blocks 같은 효율적 블록 디자인 하는 것
- layer 연결 방식 연구도 포함
- Network Architecture Search
- 프로그래밍적으로 효율적인 네트워크 구조를 정의된 탐색영역(search space)에서 찾는 것
- Knowledge Distillation
- Knowledge transfer에서 유래됐으며 larger model 처럼 역할하는 simple model 만드는 것
PREVIOUS경제