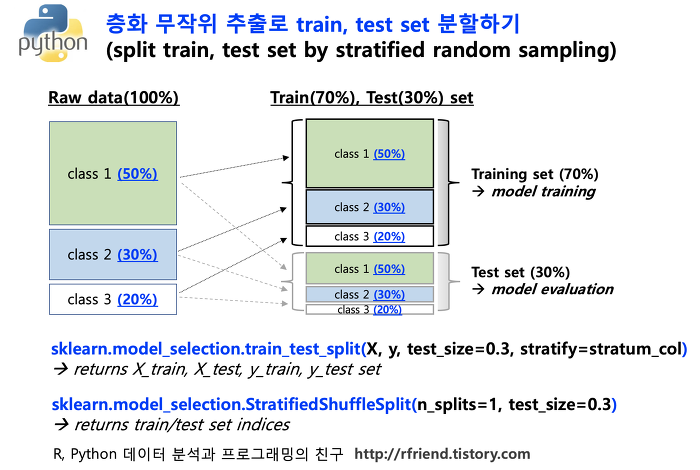
데이터 나누기
train_test_split과 StratifiedGroupKFold, StratifiedKFold 등의 다양한 split 방법이 존재한다.
여기서는 StratifiedKFold의 설명을 추가적으로 해보고자 한다.
train_test_split
- 사용할 때 간단 요령
- feature data, label data 분류할 때 헷갈리지 않는 법
- 인자 순서대로 분리한다고 생각
- 아래 예시에서 norm_data[‘value’]를 먼저 train용, test용으로 나눔 -> X_train, X_test
- 그 이후 norm_data[‘code’]를 train용, test용으로 나눔 -> y_train, y_test
- 인자 순서대로 분리한다고 생각
train_value, test_value, train_code, test_code = train_test_split(norm_data['value'], norm_data['code'], test_size=0.2, shuffle=True, stratify=norm_data['code']) # nv: norm value / nc: norm code ''' 이런식으로 구성되어 있으면 뒤의 argument 우선임 value를 train, test로 나눈 후, code를 train, test로 나누는 것 ''' - feature data, label data 분류할 때 헷갈리지 않는 법
stratify 인자
위 stratify 인자는 train_test_split 함수의 인자다. (StratifiedKFold 등과 헷갈리지 말 것)
- 필요한 상황
trainX, testX, trainY, testY 로 나눌것이라고 하고, Y는 binary[0, 1]로 구성되어있으며 0: 25%, 1: 75% 있다고 하자
trainX 안에서 0, 1인 label을 이루는 ‘데이터’ 비율을 25% 75%로 그대로 유지하고 싶다면 stratify = Y 로 설정해야함
그렇지 않으면 trainX에 10% 90% / testX에 30% 70% 이런식으로 비율이 달라질 수도 있음
StratifieldKFold
import numpy as np
from sklearn.model_selection import StratifiedKFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([0, 0, 1, 1, 0, 0, 1, 1])
skf = StratifiedKFold(n_splits=2)
skf.get_n_splits(X, y)
for train_index, test_index in skf.split(X, y):
print(f"train: {train_index}, test: {test_index}")
train: [4 5 6 7], test: [0 1 2 3]
train: [0 1 2 3], test: [4 5 6 7]
- 계층화된 data, label set을 n_splits 개로 나눔
- return 되는것은 train_test_split과 달리 인덱스임
Metrics
classification_report
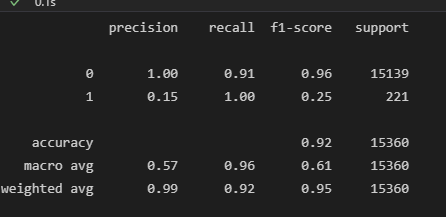
| 모델이 0이라고 한 것중 실제로 0인 비율 | 실제로 0인것 중 모델이 0이라고 한 비율 |
|---|---|
| 모델이 1이라고 한 것중 실제로 1인 비율 | 실제로 1인것 중 모델이 1이라고 한 비율 |
- 아래 그림과 같이 레이블로 나타낼 수도 있다
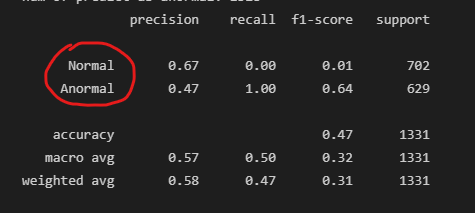
PREVIOUS경제