비지도 학습에 속하는 개념이다. 즉 레이블이 존재하지 않는다.
처음에는 레이블이 존재하지 않는다는것의 의미를 잘 이해하지 못해 아래와 같이 생각하였다.
- self-supervised를 적용해서 아래 그림과 같이 데이터가 나눠진다고 할 때 각 부분이 어디 번호인지 맞추는것이 하나의 예시라고 함
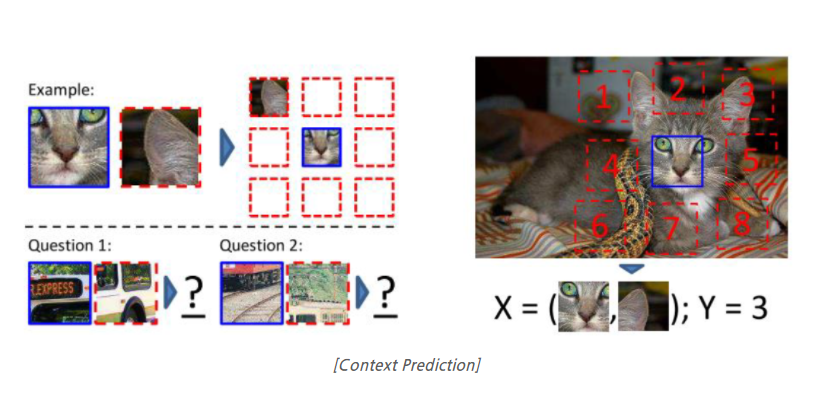
-
나는 이 번호도 레이블이라고 생각이 들어 self-supervised는 레이블이 없다는 점을 이해하지 못했다. 결론부터 얘기하자면 저 이미지가 고양이인지, 곰 인지, 혹은 특정 사물인지 분류해주는 전문가가 없어도 세상에 존재하는 수많은 데이터에 대해 위 그림과 같은 patch 작업 및 어디 번호인지 맞추게끔 학습시키는 것이 가능하다.
- self-supervised를 이해하기 위해서는 다음과 같은 생각을 해야한다.
- 여러개의 다른 모습의 의자 사진을 모두 의자라고 분류할 수 있도록 사람이 학습한다고 가정할 때 우리는 4개의 이미지를 모두 의자라는 같은 카테고리로 묶은 이후 이해를 하는게 아니라, 각 사진별로 가지고 있는 특별한 특징(예를들면 의자는 사람이 앉을 수 있는 공간이 있어야 하며 모양은 네모든 동그라미든 상관없다)을 분석하여 의자라는 결론을 내리게 된다. 즉 각 이미지별로 깊은 이해를 하고 있다.
- self-supervised도 각 데이터별로 깊은 이해를 유도하고자 하는 것이며 이를 위해 이미지를 회전시킨 상태에서 얼마나 회전됐는지 맞추게 하거나, 이미지 일부분 발췌해서 전체를 맞추게 하거나 하는등의 pretext task를 먼저 주는것이며 그렇게 어느정도 이해를 유도한 후 학습을 진행하는 방식이다.
- 이 과정들을 함축적으로 말하면 사용자가 정의한 새로운 문제(pretext task)를 사전 학습시키고(Pretraining) 그 이후
downstream task로 transfer learning을 하는 접근 방법이다.- upstream task: pre-training 단계에서 진행하는 학습 task
downstream task: transfer-learning 단계에서 적용하고자 하는 target task(커스텀 task로 봐도 될 듯)
PREVIOUS경제